
Machine Learning: A Powerful Tool for Bureau Research
Data is the lifeblood of geoscience research. Bureau of Economic Geology researchers gather reams of data from a myriad of sources. Core, cuttings, outcrops, fluids, gases, satellites, drones, seismometers, sensors, scanners, and an array of equipment all provide huge amounts of data for cataloging and analysis. This was once an incredibly daunting task, but, for several years now, Bureau scientists and engineers have utilized machine learning (ML) as an extremely powerful tool to expedite and enhance their research.
One definition of “machine learning” describes it as: “The use and development of computer systems that are able to learn and adapt without following explicit instructions, by using algorithms and statistical models to analyze and draw inferences from patterns in data.” We recently set out to find researchers who benefit from machine learning practices and to learn about how it is used here at the Bureau. Here’s what we found:
About a year ago, Deputy Director Jay Kipper organized a SHARE session for 40 researchers to share insights and to learn from each other about the Bureau’s uses for artificial intelligence and machine learning. The session summary stated, “There are some important opportunities for artificial intelligence/machine learning (AI/ML) in geosciences, for example, geologic feature classification, automated fault mapping, prediction of rock properties, denoising, surrogate modeling, natural hazard forecasting, and adaptation, etc. AI/ML is not new; it has been in existence for more than 80 years. Geoscientists have been using it since as far back as the 1980’s. AI/ML use came in different waves. Several Bureau researchers are involved in AI/ML-related research now.”
The summary continued, “To properly harness Big Data analytics and ML, we need to be realistic, ask the right questions, use the right set of attributes, perform data conditioning, and implement domain expertise. There is no single widget to solve all problems. While using ML in our data set, we need to be aware of the fundamental mathematics and assumptions underlying those algorithms, their pros and cons with different types of data sets, bias in the training data, the required form of input data standardization, and generalizability of the models.”
“Geoscience data sets have unique features compared to other domains where some ML algorithms were developed. Perhaps it’s time to develop new algorithms and approaches to solve some of the grand challenges in ML. There is room for collaboration with computational experts and to provide domain expertise to ML models. What and how do geoscientists give back to the broader ML community?”
“AI/ML has helped geoscientists diversify their skills, including new employment opportunities in tech companies. However, there is a difference between academia and industry research in ML. Many routine industry problems can be solved by state-of-the-art algorithms, but to derive good quality research value, one needs to develop new approaches.”
The summary concluded, “Geoscientists need to collaborate with tech companies and offer domain expertise to their models. Some of the research topics that were discussed in the session (for example, variance and bias in ML models) were addressed by computer scientists and statisticians years ago. Some of the new research may include working with core samples, hand-drawn diagrams, joint analysis of multiphysics data, and physics-informed ML, etc. We may also want to see how we can convert science-based research to socioeconomic values using ML.
Also discussed were some misadventures of ML. For example, the degraded performance of channel detections on real data compared to synthetic data.”
Senior Research Scientist Dr. Sergey Fomel reported, “My group (the Texas Consortium for Computational Seismology, or TCCS) pioneered the use of machine learning in analyzing 3D seismic images for automating interpretation tasks traditionally done by human interpreters: picking geological faults, salt bodies, and channels. We also found numerous other applications of machine learning in analyzing seismic data and solving tasks such as data reconstruction, noise attenuation, modeling seismic wave propagation, improving the resolution of seismic images, and the accuracy of full-waveform inversion.”
Dr. Fomel went on, “Bureau senior researcher Zoltan Sylvester and I are teaching a graduate course on Machine Learning Applications in Geosciences, where we walk students through the experience of using ML tools in solving real-world problems in analyzing geoscience data of different kinds: passive and reflection seismic, well logs, thin sections, satellite images, etc. We also successfully taught this material in the industry in the form of a short course.”
“Other people at the Bureau with interesting stories about their use of machine learning are Yangkang Chen (ML for earthquake detection), Hongliu Zeng (ML for seismic reservoir characterization), and Alex Sun (ML for carbon capture, utilization, and storage monitoring).”
Research Associate Dr. Shuvajit Bhattacharya shared, “We have used ML for automated data filtering, rock type classification, and rock property predictions in an integrated manner that honors geology.”
“Subsurface data denoising is critical to accurate interpretation. We have developed a new workflow on multiattribute-based unsupervised ML and supervised autoencoder–decoder networks for large data segmentation, removal of bad samples from petrophysical logs from hundreds of boreholes, and reconstructing signals. We integrated our ML solutions with rock data and identified the reasons behind bad samples in some locations in the Permian Basin. This allowed us to build more accurate petrophysical models in areas lacking core data.”
Dr. Bhattacharya went on, “We have been able to incorporate a certain amount of geologic and petrophysical concepts and quantitative relationships directly into ML modeling or physics-based ML. Current ML models underutilize well-known interdependence or conditional dependence (static and dynamic) structures existing among geologic attributes. We quantify this degree of interdependence in a stratigraphic and petrophysical context and use it as a constraint on rock property estimates. This enables us to predict rock properties in areas with limited and scattered data with high accuracy and consistency at a basin scale.”
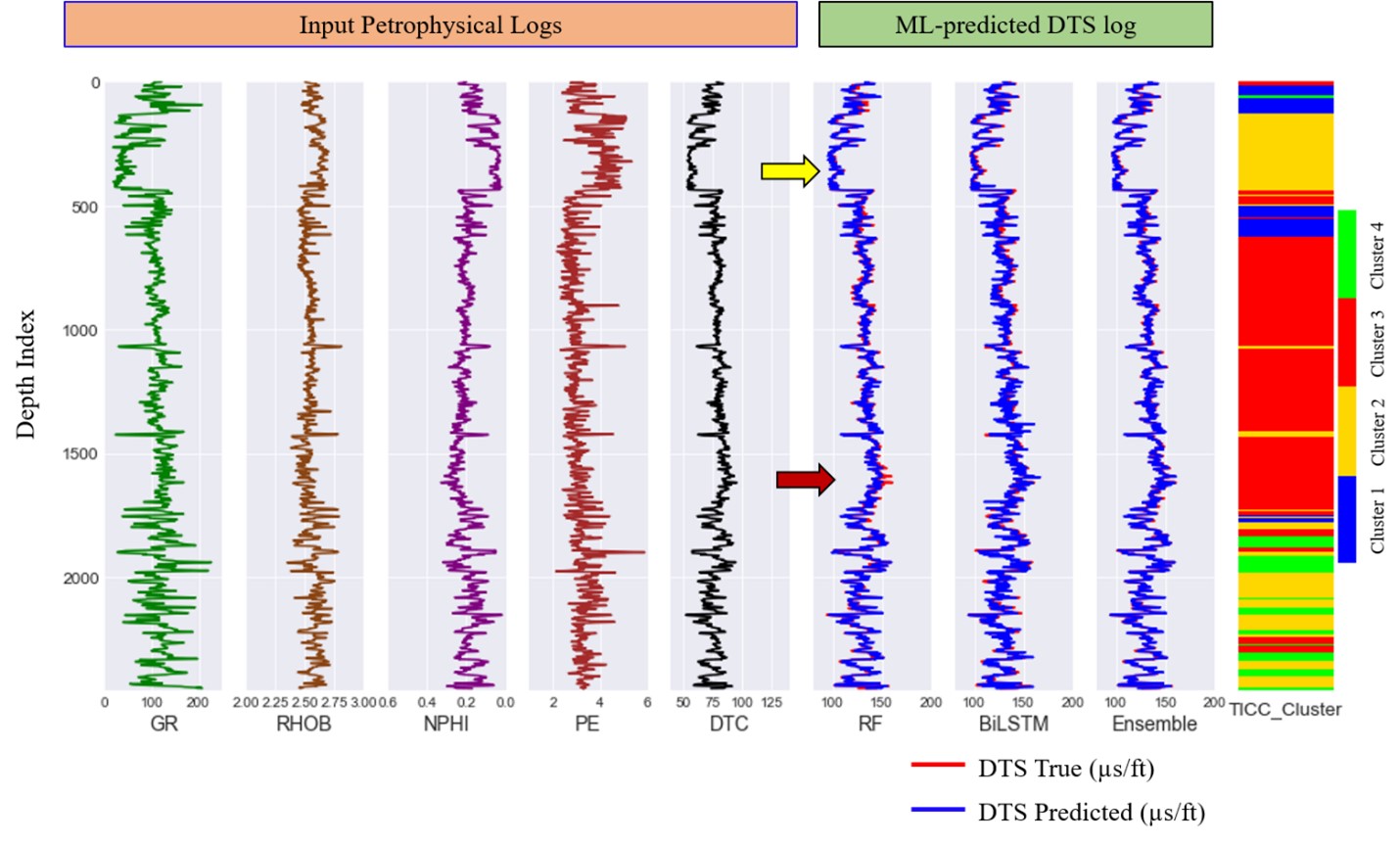
Figure 1. Results from class-based ensemble ML model for shear sonic slowness (DTS) prediction in a test well. The yellow arrow indicates where the random forest (RF) algorithm outperforms bidirectional long–short term memory (bi-LSTM,) and the dark red arrow shows the opposite pattern across different clusters. The ensemble model combines both models and presents the best possible predicted shear sonic curve (from Bhattacharya, 2022, Geophysics, https://doi.org/10.1190/geo2021-0478.1).
“Manual interpretation of complex geologic features (such as salt inclusions, mass transport deposits, etc.) on large geophysical data is time intensive, and the incremental knowledge gain often has minor impacts at a large scale. We used unsupervised and semisupervised ML to label and map some very complex features on the entire 3D seismic data set, which we then updated at a few locations based on geologic knowledge. The model can be reiterated frequently as new geologic information becomes available. This process helped us to quickly interpret large volumes of data and reduce some degree of human bias while preserving important geologic information in the interpretation.”
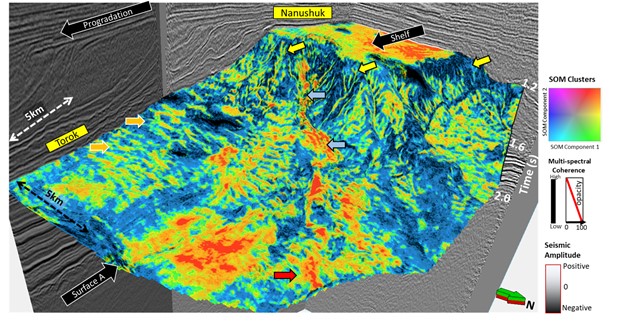
Figure 2. A 3D view of the Nanushuk–Torok succession with multispectral coherence attribute corendered with unsupervised self-organizing map-based (SOM) facies clusters along surface A. The orange arrows: the sediment wave; yellow arrows: channel; blue arrows: canyon; red arrow: basin floor fan (from Verma and others, 2022, Chapter 16, Deepwater Sedimentary Systems. https://doi.org/10.1016/B978-0-323-91918-0.00015-3). Data courtesy of the State of Alaska, Department of Natural Resources, Division of Oil & Gas, AS 43.55 Exploration Tax Credit Project.
Research Scientist Dr. Toti Larson explained, “Characterization of subsurface geological reservoirs has benefited from over 150 years of oil and gas exploration and production, yet our knowledge of the subsurface remains hindered by the inherent heterogeneity and high degree of spatial variability that is typical of sedimentary depositional systems. Core-based data provide the most direct measurements of rock attributes that are required to develop static reservoir models, yet a persistent issue remains in our ability to upscale discrete measurements obtained from core samples to reservoir-scale models, especially when trying to capture thin-bedded heterogeneity that is common to sedimentary rocks.”
Dr. Larson continued, “The Mudrock Systems Research Laboratory (MSRL) has developed a machine learning workflow called CorePy that improves visualization and data integration of high dimensionality, spatially complex, and multimodal core-based data sets. Using machine learning, CorePy predicts core-based rock facies from open-hole triple combo wireline log suites (gamma ray, deep resistivity, bulk density, and neutron porosity). This is accomplished with core-based formation-specific rock facies training data sets that cover the Wolfcamp, Bone Spring, Spraberry, Austin Chalk, Eagle Ford, and Haynesville formations. Importantly, this workflow can be deployed using open-hole wireline logs alone, which expands the use of core-based facies classifications ‘beyond the core’ to the basin scale.”
Senior Research Scientist Dr. Zoltan Sylvester reported, “Our research group (Quantitative Clastics Laboratory, or QCL) has been using machine learning techniques to detect individual grains in images of detrital zircons and modern sand samples.”
“Detrital zircon grains are an important source of information when it comes to the age, provenance, and stratigraphic correlation of sediments. Normally, the focus is on the age of the grains and other potentially useful parameters such as grain size and shape are usually ignored. However, this information can be extracted using ML workflows from images of zircon grains. We use a Unet-type convolutional neural network (CNN) to perform semantic segmentation. The training data consists of 256x256 pixel image tiles, derived from a set of large images with thousands of manually outlined grain boundaries. The output is post-processed using conventional image processing approaches, so that individual grains are detected and their size and shape can be quantified (Fig. 3).”

Figure 3. Detrital zircon grains detected using a CNN model in an image that was not used in training. Image courtesy of Daniel Stockli, Department of Geological Sciences, Jackson School of Geosciences.
Dr. Sylvester continued, “The same Unet network architecture can be also used to detect grains in images of modern sand. However, the images are quite different, and a new ML model needs to be trained with new training data. We isolate images of individual sand grains and perform unsupervised clustering so that grains of similar shape and color are sorted into the same clusters. It is also possible to measure shape parameters such as the aspect ratio (Fig. 4). This workflow has the potential for quickly deriving a large amount of data from any sand sample and to compare and contrast sands of different origins.”

Figure 4. Sand grains from Half Moon Bay, California; the grains were all resized to the same scale so that the focus is on shape and color. Grains are sorted according to their aspect ratio.
As described by the Bureau’s researchers, machine learning has become a vital tool for a broad range of research efforts. As it is increasingly utilized and adapted, machine learning will play a key role in keeping the work of the Bureau of Economic Geology at the cutting edge of global energy, environmental, and energy economics research.

